생각 이상으로 많이 생기는 Behavior, DTO 문제
단순 조회라도 Controller -> Service -> Behavior -> Repository 로 이어진다.
그리고 그 레이어간의 통신시마다 각자의 레이어들이 요구하는 DTO 를 만들다보면, 필드 값들이 매우 유사한 많은 Class 가 정의된다.
특히 단순 아이디 조회건의 경우에는 형식적인 각 레이어 관련 class 들이 생성되고 그에 대응하는 동일 필드의 DTO 들이 정의되며, 그를 위한 변환 로직이 들어간다.
 많다...
많다...
각 도메인의 지식이 명확하고 이해도가 깊다면, 모든 Layer 에서 참고할 수 있는 Top-Level 레이어 수준으로 Entity (JPA Entity 말고) 를 만들어볼 수 있겠지만, 현실은 쉽지 않았다. 전사 도메인이 그렇게 일관된 통일성이 있는게 아니라 A 비즈니스 팀 에서 해야할 일을 B 비즈니스 팀에서 하는 일도 있고 자주 바뀌기에 이것에 대응하려는 설계는 참으로 어려웠다.
하지만 정석은 언제나 통한다고 생각한다. 많은 시간을 들여 분석해가며 설계하면 이런 점까지 커버할 수 있는 시스템을 만들 수 있다.
하지만 이번에는 일단 초기에 만든 규칙대로 다수의 파일 생성도 감안하며 가는 방식을 선택했다. 후에 리팩토링을 통해서라도 개선하고 싶다.
API 분할과 정의 문제
전 글 에서 언급한 데이터 토막치기 로 간단히 데이터를 합쳐서 한방에 내려주는 방식이 아닌 각각의 논리적 단위로 데이터를 가져오는 방식으로 변하면서, 서버 API 설계가 상당히 중요해졌다.
API 를 전체적으로 알지 못하면 같은 데이터가 필요할 때 비슷한 기능의 API 가 생성될 수도 있고, 적절한 관리가 안될 경우 나중엔 비슷비슷한 응답의 endpoint 만 조금씩 다른 API가 많아질 수 있다.
이번에 작업한 내용은 주문정보 라는 컨텐츠 하나였지만 그 안에서도 서로 비슷한 필드 몇개만이 다른 endpoint API 가 몇개 정도 존재하게 되었고 그대로 product 배포 상태이다.
이 점은 문서화와 관련이 깊다고 생각한다.
나중에 문서화를 위해 다급히 swagger 를 붙이고 주석 annotation 을 코딩했지만 만족스럽진 않다.
 문서 정리는 언제나 귀찮다
문서 정리는 언제나 귀찮다
개발단계에서 보다 쉽게 API 를 파악할 방법이 있다면 좋겠는데.
Client 에서의 요청 증가 문제
역시 데이터 토막치기 로 인해 기존에 한방에서 여러 요청으로 나뉘면서 Http Request 의 숫자가 늘어났다.
데이터 각자가 자신이 필요한 데이터만 응답하기에 경량화된건 사실이다. 하지만 화면에서는 여전히 여러 데이터가 필요하고 그 데이터를 구하려면 필요한 수 만큼의 API 요청을 해야 한다.
복잡한 도메인이 포함된 비즈니스로 구성되는 컨테이너의 경우 많은 요청으로 인해 느릴 수밖에 없고 네트워크의 Latency 가 나쁜 상황에서는 몇배로 느려진다.

이 때문에 논리적인 데이터 토막을 잘 정의하는게 매우 중요하다.
데이터를 과하게 합쳐 응답할 경우 특정 UI 나 비즈니스만을 위한 API 가 되고, 과도하게 나눠 응답할 경우 Client 로직이 복잡해지고 Http request 가 증가한다.
이에 대해서는 확실한 기준을 세우지 못했다. 대략적으로 만든 아래와 같은 기준이 있을 뿐이다.
- 반복적으로 조회되며 변경율이 낮은 상수 데이터는 앱 초기에 로딩하여 store 에 저장한다
- 키 조회 API 는 분리한다 (상품, 주문, 취소, 반품 …)
- 정책 API 는 분리한다 (취소가능, 배송지 변경가능, 접수 수정가능 …)
- 복수의 데이터의 조합으로 결정되는 데이터는 합친다 (회원 특별등급, 3P,Retail 배송상태 …)
- 데이터의 변경/생성/삭제 에 대해서는 최소한의 파라미터로 한번의 트랜잭션으로 처리한다
Client 로직에서의 Container 단위 정의 문제
데이터를 분할해서 받았으니 역시 분할된 데이터를 조립해야 한다.
그 영역은 Container 라 부르는 Redux Store 에 connect 되는 영역에서 처리하기로 했다.
각 Ducks 를 확장한 ReDucks 에서 selector entity 들의 데이터를 잘 조합하는 Container 용 selector 를 만든다. (selector 는 메모이징을 지원하도록 reselect 를 사용했다)
Container 는 특정 목적의 비즈니스의 집합이라 UI 와 강하게 결합되기에 그냥 한파일에 selector 를 넣었다.
이렇다보니 Container 를 잘못 정의할 경우 엄청난 크기의 selector 가 만들어진다. 그렇다고 모든 UI Component 들을 Container 화 할 경우 모든 UI 에 entitiy selector 가 달리게 되고, 데이터 구조 변경에 강한 영향을 받게 된다.
현재는 데이터의 응집력(나름대로의…) 단위로 나눠두긴 했는데, 이것도 불명확하긴 매한가지.
참고할 만한 기준따위 있을리도 없고, 결국에는 실전 운영으로 타협점을 찾아가는게 좋을 듯 하다.
Webpack Code Splitting 문제
asset(js, css, images…)들의 로딩은 단일 서버 운영에서는 문제가 일어나지 않는다.
하지만 복수의 서버로 운영되는 환경에서 운영되는 배포 프로세스중에는 Canary Release 라는 방식이 있다.
Canary Release 는 새로운 버전의 소프트웨어를 운영 환경에 배포할 때, 전체 사용자들이 사용하도록 모든 인프라에 배포하기 전에 소규모의 사용자들에게만 먼저 배포함으로써 리스크를 줄이는 기법이다.
- 너굴너굴 블로그
이 환경에서는 일정 기간동안은 asset 의 버전이 다른 미배포 서버와 canary 서버가 다를 수 있는데 canary 서버의 변경이 있는 상태에서 변경되지 않은 미배포 서버의 asset 을 로딩할 경우 asset 버전 불일치로 인한 장애가 발생할 수 있다.
꼭 canary 방식이 아니더라도 순차적으로 N대씩 배포되는 환경에서는 문제가 발생한다.
Webpack 에서는 기본 전략으로 asset 파일들을 hash 문자열로 변환하여 배포시마다 파일이름이 [hash].[ext] 형식으로 번들되어 배포되는데, 문제는 canary 서버가 배포된 뒤 이 서버에서 asset 을 미배포 서버에 요청하게 되는 일이다. 당연히 해당 asset 은 없어서 404 error 가 발생한다.
파일 이름을 강제로 고정 이름 (예를 들면 534fsdnfg23543gf.js 가 아닌 main.js) 으로 정해도 되지만, 이 경우 client cache 를 피하기 어렵다.
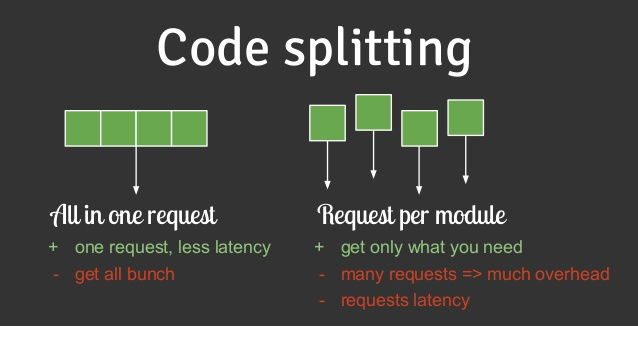
운 좋게 canary 서버가 요청한 asset 을 canary 가 받았다 하더라도, Chunck 등의 Code Splitting 이나 Lazy Loading 등을 적용해뒀다면 Chunk Loading Error 도 보게 된다.
처음에는 장애 포인트를 알 수 없어서 Canary Release 를 건너뛰고 항상 Deploy All 을 했었다.
해결책은 S3빌드번호를 webpack 번들링 타이밍에 인자로 넘겨 output 설정에 Public Path를 만드는 방법이었다.
Public Path 가 고정되니 배포 Scope 으로 asset 을 요청하게 되고 자신의 배포버전에 맞는 asset 을 서버에서 로딩하도록 유도할 수 있었다.
이부분에서 꽤나 많은 시행착오가 있었던걸로 기억한다.
익숙하지 않은 도구들 문제
styled-component

스타일 도구로 styled-component 를 사용했는데, 기존의 css 와 className 개념과는 아주 달랐다. Component 에서 Style 의 요소를 Component 로 분리하는 생각이 생각대로 잘 되지 않았다.
별도 파일로 분리해야 하는 것인가, 기존 css 처럼 하나의 파일에 전부 모아두고 selection import 하는 방식인 것인가부터, 어느 레벨로 그룹해야 하는지도 혼란스러웠다.
문법적으로도 3.x 버전과 4.x 버전의 과도기에 사용해서 라이브러리의 구조가 변했고, 대응하느라 리소스의 낭비도 있었다.
사용하면서 내린 나름의 결론은 이렇다.
- 각 컴포넌트는 가급적 React.Fragment 로 래핑한다
- 부모 레벨이 자식 컴포넌트의 스타일을 지정할 수 있게 한다. StyleComponent 로 자식을 감싸서 사용한다는 뜻이다
- StyleComponent 든 DataComponent 든 네이밍과 파일 단위는 동일하게 한다. 사용 측에서는 이 컴포넌트가 Style 인지 Data 인지 알 필요가 없다.
현재 (2018.11.23) 운영 배포된 소스는 위의 룰을 지키지 못했다. 천천히 수정해야 할 일이다.
Redux-Saga

Redux-Saga 의 사용에 미숙하여 여러 착오를 겪었다.
제일 심하게 겪은 문제는 take 관련인데 Ajax 등의 비동기 Side-Effect 를 동반하는 Task 일 경우 같은 요청이 다수가 중복된다면 첫번째만 처리하는 것이 보통 효율이 좋다. 이런 경우는 대부분 사용자의 반복된 클릭등으로 요청되는게 대부분이기 때문이다.
Saga 에서는 Helper 함수로 takeLatest, takeEvery, takeLeading 등을 지원한다
- takeEvery
- takeLatest
- takeLeading
개발 초기에는 대부분의 Saga Watcher 에 takeLeading (1.x) 을 걸어두었다. 중복 요청일 경우 두번째는 무시하기 위해서이다.
하지만 나중에 테스트와 액션 리포트를 보면 사용자의 반복 요청에 막히는 것은 거의 없고 오히려 특정 사이드이펙트 action watcher (트리거 action이 여러개 존재하는 watcher) 가 서로 다른 action dispatch 에 영향받게 되면서 나중 요청을 전부 씹는 상황이 발생했다
예를 들면 주문 상세를 트리거하는 ORDER_DETAIL 액션으로 주문 A 를 trigger 했다가 바로 B 를 trigger 하면 주문 A 의 정보를 로딩하는 watcher 들이 takeLeading 방식이라 나중에 들어온 B 정보 action 을 dispatch 하지 않고 주문 A 관련만을 처리하게 되는 것이다.
take 디자인에도 생각없이 하면 안된다는 걸 깨닫고 액션과 UI 의 관계에 따라 다른 take 전략을 사용해야 한다는 걸 깨달았다. 잘 모르겠으면 take helper 들을 안쓰는 것도 좋은 방법인것 같다.
fork 된 액션은 부모의 try-catch 에 영향이 없다라든지 call 과 fork Blocking 차이라든지 하는 Redux-Saga 이해도가 부족한 것에서 오는 어려움도 있었지만 이런건 Document 를 잘 봤으면 해결될 문제라…
결론
CS 상담 시스템 개편이 현재 시간 기준 한창 테스트중이다.
여러모로 아쉬운 점이 많은 프로젝트였다. 여기엔 적지 않았지만 잘못된 시간분배나 플래닝, 계획들도 큰 장애거리였다.
테스트 결과와는 관계없이 기록을 남겨 나중에 기술 선택에 좀더 도움이 되길 바랄 뿐이다.
